vector日志采集-快速开始
本文默认已经有一丢丢lua基础
vector 采集流程
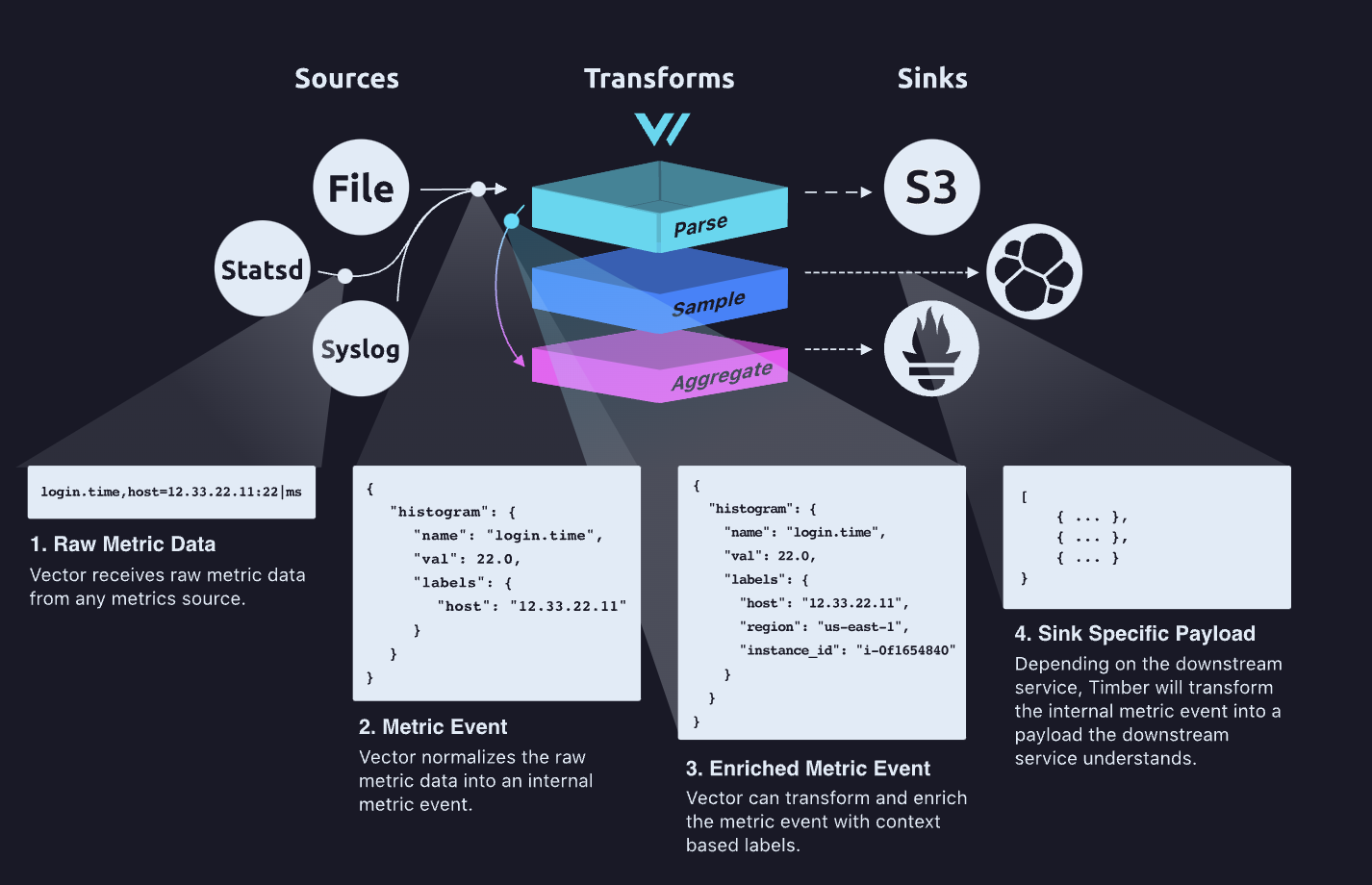
vector官网给出的三步走战略,结合具体配置,设置采集源头—>进行数据转换—>保存转换好的数据。
# 从哪采集
[sources.generate_syslog]
type = "demo_logs"
format = "syslog"
count = 100
# 数据转换
[transforms.remap_syslog]
inputs = [ "generate_syslog"] # 转换的输入来自generate_syslog过程的返回值
type = "remap"
source = '''
structured = parse_syslog!(.message)
. = merge(., structured)
'''
#保存到哪
[sinks.emit_syslog]
inputs = ["remap_syslog"] # 保存的输入来自remap_syslog过程的返回值
type = "console" # 把结果直接输出到终端上
encoding.codec = "json"这相当的友好,除了toml配置,你还能使用json或者需要游标卡尺的yaml。
采集实战
采集源头(sources)和 保存到哪(sinks)设置起来很容易,官网给出了相关的文档,你能看到很多sources、sink以及我们即将重点实战的数据转换(transforms)。
实战案例背景
假设有一个程序会通过syslog输出日志,我们需要采集含有ohayo字符串的日志,并把它保存到一个文件中。
采集源头:syslog
数据转换需求:含有ohayo字符串的日志
保存:文件
vector 采集配置
采集源头,监听本机的/dev/log套接字,syslog与vector会通过这个套接字进行进程间通信。
[sources.syslog_1]
type = "socket" # 类型采用套接字方式
mode = "unix_stream" # 采用unix流的方式
path = "/dev/log" # 监听套接字路径数据转换,这里我使用的是lua,vector官网在极力推它们的remap,甚至给出lua5.4比remap慢了60% && lua只能在运行时才会出现问题,这不安全的恐怖言论。
O(2n)、O(3n)都是O(n),长板凳、矮板凳都是板凳。根据剃刀原理…这就是我选lua的理由。
PS: remap在面对格式规范的日志输出,要比lua更加方便。而且在启动vector时会进行静态检查。
让我们先看一下,lua怎么在vector中转换数据的吧!下图是官网文档。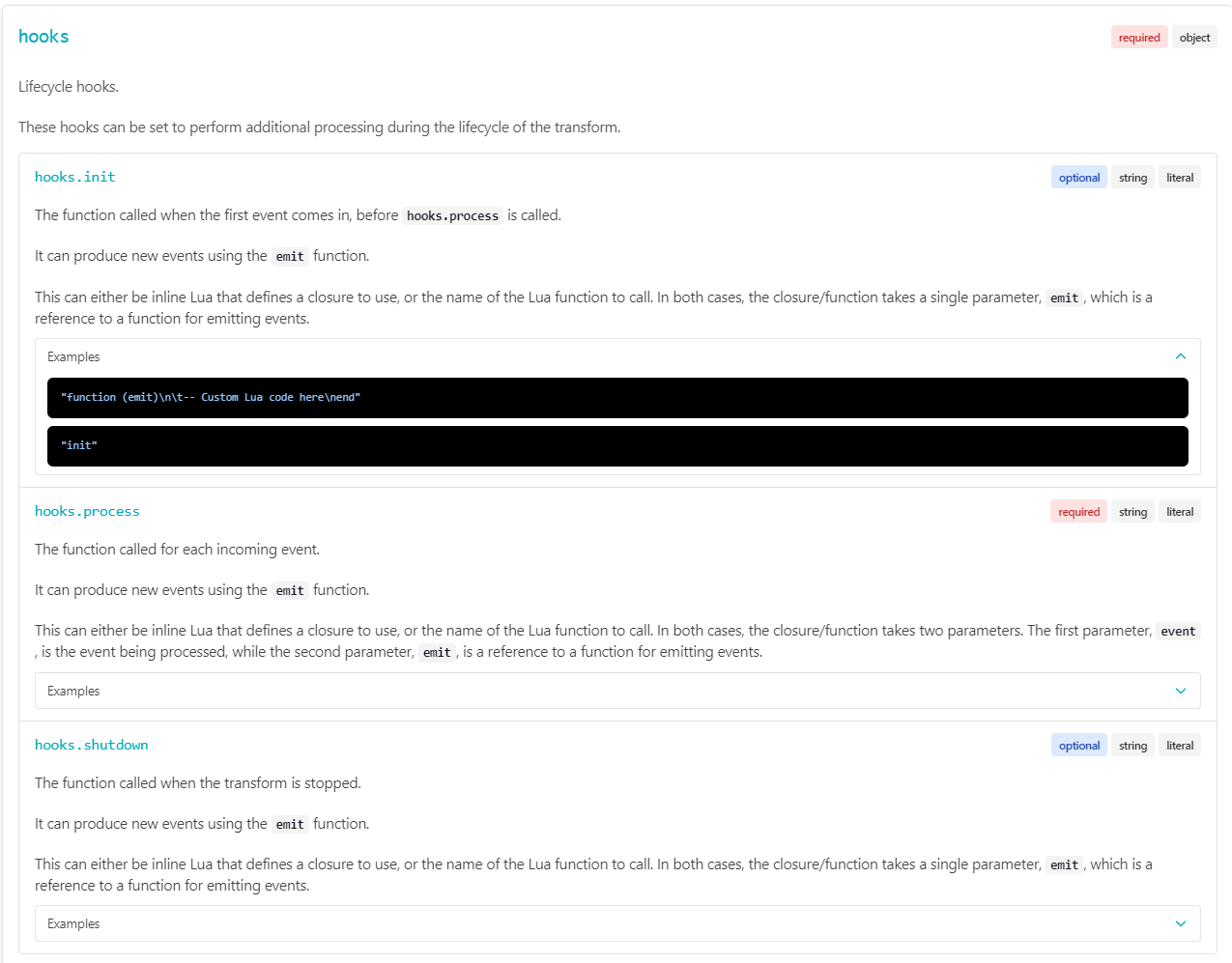
vector需要我们在配置中注册三个函数,init | process | shutdown,第一条日志来的时候,会执行init函数,然后会执行process,当转换结束时,会执行shutdown。
注意,init只有在第一条日志来的时候才执行,shutdown在关闭时执行,而process在每条日志来的时候都会执行。
结合配置格式填写如下
[transforms.milestone_syslog_2]
# General
type = "lua" # 转换类型lua
version = "2" # 转换api版本,1已经被弃用了。
inputs = ["milestone_syslog_1"] # 从采集源头获取数据
search_dirs = ["scripts"] # lua导包的搜寻路径。这里是相对路径./scripts
source = "rd = require('record')" # 引入资源,这里面可以写代码哦
hooks.process = "rd.process" # 注册 process函数-- @filename record.lua
local M = {}
function M.process(event, emit)
if string.find(event.log.message) then
emit(event)
end
end
return M解释一下,vector会把每一个从source采集日志,包装成一个table,日志的内容可以用event.log.message获取,emit函数会把event结构的table发送到sink存储层进行保存。
保存的内容是 event.log,这个table的格式如下。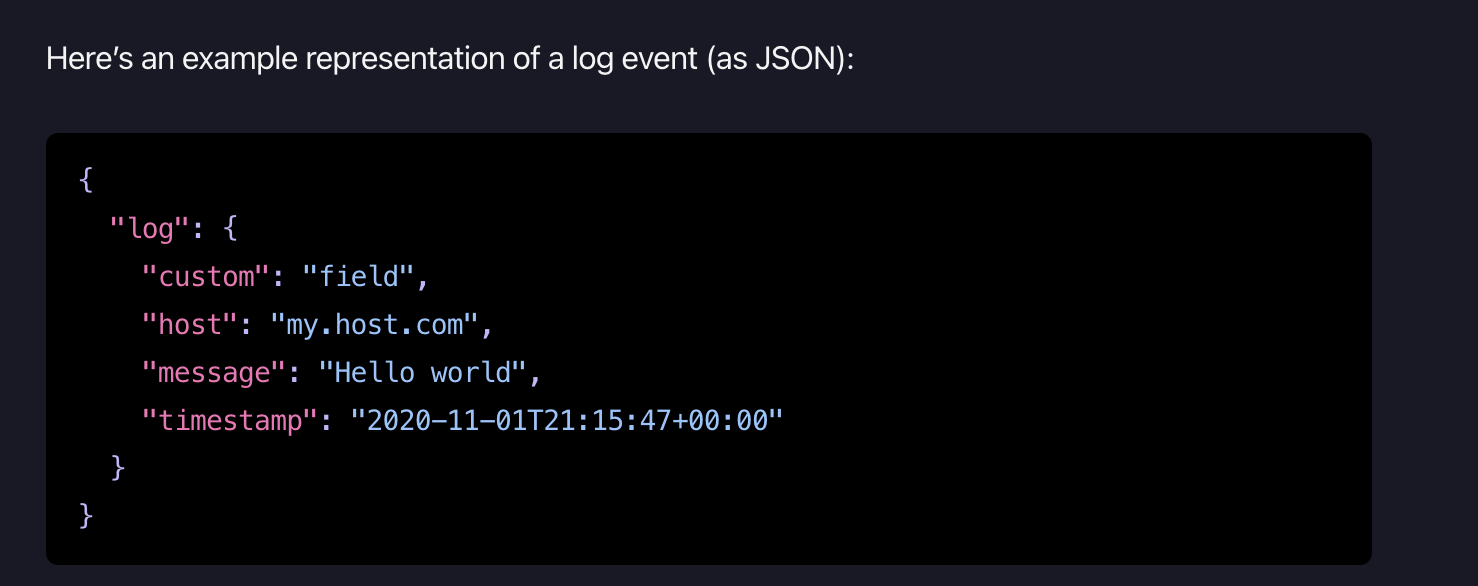
接着设置保存,从转换层(transform)拿到数据,编码成text,设置保存路径即可。
[sinks.milestone_record_file]
type = "file"
inputs = ["milestone_syslog_2"]
idle_timeout_secs = 30
encoding.codec = "text"
path = "/tmp/vector-%Y-%m-%d.log"完整配置文件如下
[sources.syslog_1]
type = "socket" # 类型采用套接字方式
mode = "unix_stream" # 采用unix流的方式
path = "/dev/log" # 监听套接字路径
[transforms.milestone_syslog_2]
# General
type = "lua" # 转换类型lua
version = "2" # 转换api版本,1已经被弃用了。
inputs = ["milestone_syslog_1"] # 从采集源头获取数据
search_dirs = ["scripts"] # lua导包的搜寻路径。这里是相对路径./scripts
source = "rd = require('record')" # 引入资源,这里面可以写代码哦,这个lua文件是自己写的哦。
hooks.process = "rd.process" # 注册 process函数
[sinks.milestone_record_file]
type = "file"
inputs = ["milestone_syslog_2"]
idle_timeout_secs = 30
encoding.codec = "text"
path = "/tmp/vector-%Y-%m-%d.log"sudo vector --config xxx.toml就可以进行采集了。
总结
如果你对lua有一定了解,那么这篇文章就够了,你可以在转换层做全部事情。BTW,官网文档对各种API写的相当全,比较不错的参看。本文对快速开始使用vector来说已经足够了,如果你的日志是标准内容,请首选remap,快是真的快。